在开发后端服务时,如果数据库集成实施不正确,很容易产生问题。本文将告诉您在现代服务中使用关系数据库的一些最佳实践,还将向您展示自动生成和保持最新模式可能不是一个好主意。
我将使用Flyway进行数据库迁移,使用Spring Boot轻松设置,并使用H2作为示例数据库。
我没有介绍关于什么是迁移以及它们如何工作的基本信息。以下是 Flyway 的好文章:
问题
很久以前,开发人员通过独立于应用程序应用脚本来初始化和更新数据库。但是,现在没有人这样做,因为它很难在适当的状态下开发和维护,从而导致严重的麻烦。
如今,开发人员主要使用两种方法:
- 自动生成,例如JPA或Hibernate – 数据库通过比较类和当前 DB 状态来初始化并保持最新;如果需要更改,则适用。
- 数据库迁移 – 开发人员增量更新数据库,并且更改在启动时自动应用,数据库迁移。此外,如果我们谈论 Spring,有一个开箱即用的基本数据库初始化,但它不如 Flyway 或 Liquibase 等类似物先进。
Hibernate 自动生成
为了演示它是如何工作的,让我们使用一个简单的例子。具有三个字段的表用户 – id, user_name, email:
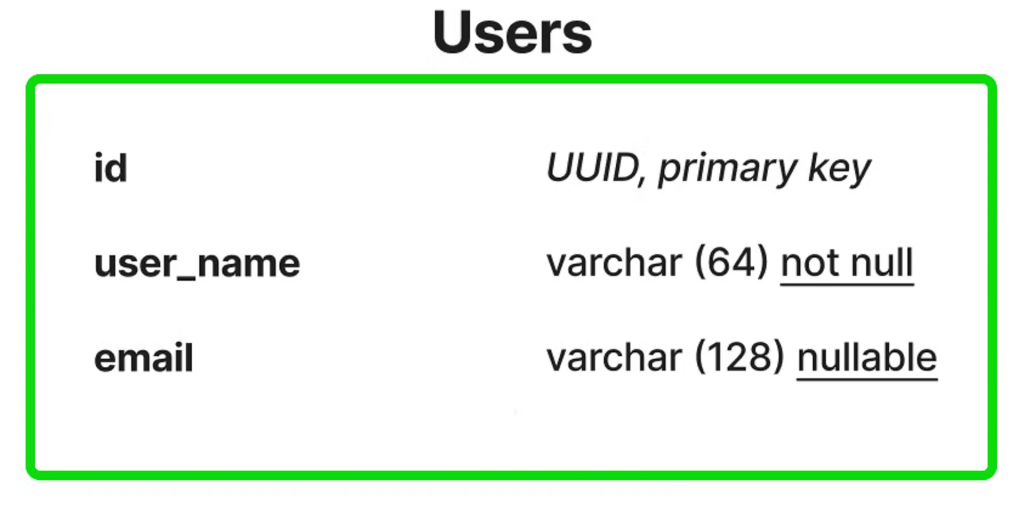
用户表表示
让我们看一下 Hibernate 自动生成的那个。
休眠实体:
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue
private UUID id;
@Column(name = "user_name", length = 64, nullable = false)
private String userName;
@Column(name = "email", length = 128, nullable = true)
private String email;
}
为了使架构保持最新,我们需要 Spring Boot 配置中的这一行,它在启动时开始执行此操作:
jpa.hibernate.ddl-auto=update
并在应用程序启动时从休眠状态登录:
Hibernate: create table users (id binary(255) not null, email varchar(128), user_name varchar(64) not null, primary key (id))
自动生成后,它创建id的binary最大大小为 255 太多了,因为UUID它只包含 36 个字符。所以我们需要使用UUIDtype 来代替,但是它不会以这种方式生成。可以通过添加此注释来修复它:
@Column(name = "id", columnDefinition = "uuid")
但是,我们已经将 SQL 定义写入列,这打破了从 SQL 到 Java 的抽象。
让我们用一些用户填写表格:
insert into users (id, user_name, email)
values ('297a848d-d406-4055-8a6f-4a4118a44001', 'Artem', null);
insert into users (id, user_name, email)
values ('921a9d42-bf14-4c3f-9893-60f79cdd0825', 'Antonio', 'antonio@gmail.com');
添加新列
例如,让我们想象一下,一段时间后,我们想向我们的应用程序添加通知,然后跟踪用户是否想要接收它们。所以我们决定向receive_notifications表用户添加一列,并使其不可为空。
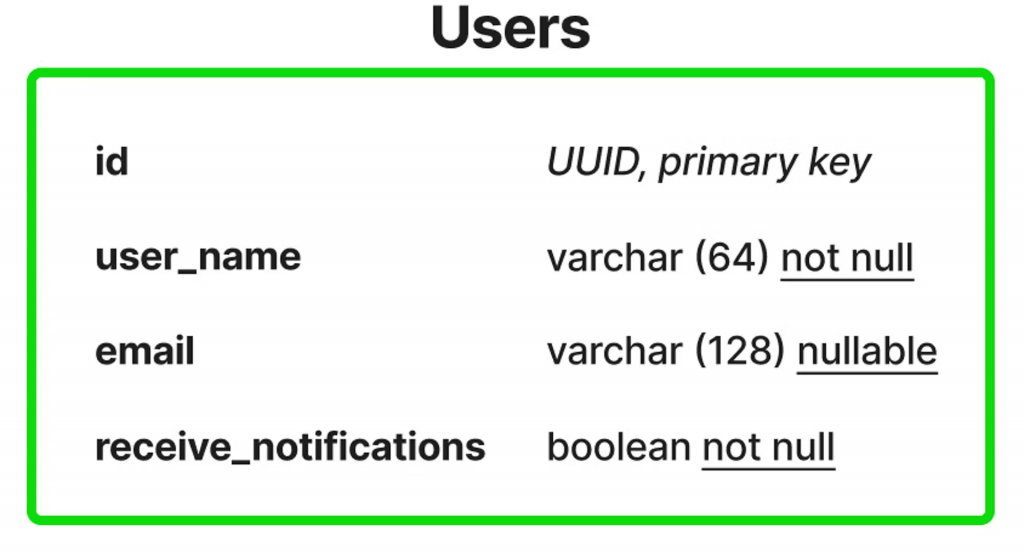
添加新列后的用户表
这意味着在 Hibernate 实体中,我们添加了新列:
@Column(name = "receive_notifications", nullable = false)
private Boolean receiveNotifications;
启动应用程序后,我们在日志中看到错误并且没有新列。这是因为表不为空,我们需要为现有行设置一个默认值:
Error executing DDL "alter table users add column receive_notifications boolean not null" via JDBC Statement
我们可以通过再次添加 SQL 列定义来设置默认值:
columnDefinition = "boolean default true"
从 Hibernate 日志中,我们可以看到它有效:
Hibernate: alter table users add column receive_notifications boolean default true not null
但是,假设我们需要receive_notifications更复杂的东西,例如,真或假,这取决于电子邮件是否已填写。仅使用 Hibernate 是不可能实现该逻辑的,因此无论如何我们都需要迁移。
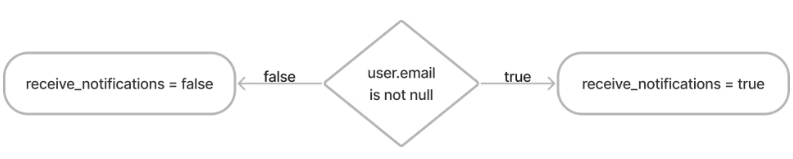
receive_notifications 的更复杂的默认值
综上所述,自动生成和更新模式方法的主要缺点:
- 它是 Java 优先的,因此在 SQL 方面不灵活,不可预测,首先面向 Java,有时不会按照您期望的方式执行 SQL。您可以编写一些 SQL 定义来执行它,但与纯 SQL DDL 相比它是有限的。
- 有时无法更新现有表并对数据进行处理,无论如何我们都需要 SQL 脚本。在大多数情况下,它最终会自动更新模式并保持迁移以更新数据。在迁移中避免自动生成和执行与数据库层相关的所有事情总是更容易。
此外,在并行开发方面也不方便,因为它不支持版本控制,而且很难判断模式发生了什么。
解决方案
以下是在不自动生成和更新模式的情况下的外观:
用于初始化数据库的脚本:
资源/db/migration/V1__db_initialization.sql
create table if not exists users
(
id uuid not null primary key,
user_name varchar(64) not null,
email varchar(128)
);
用一些用户填充数据库:
资源/db/migration/V2__users_some_data.sql
insert into users (id, user_name, email)
values ('297a848d-d406-4055-8a6f-4a4118a44001', 'Artem', null);
insert into users (ID, USER_NAME, EMAIL)
values ('921a9d42-bf14-4c3f-9893-60f79cdd0825', 'Antonio', 'antonio@gmail.com');
添加新字段并将重要的默认值设置为现有行:
资源/db/migration/V3__users_add_receive_notification.sql
alter table users
add column if not exists receive_notifications boolean;
-- It's not a really safe with huge amount of data but good for the example
update users
set users.receive_notifications = email is not null;
alter table users
alter column receive_notifications set not null;
如果我们选择,没有什么能阻止我们使用休眠。在配置中,我们需要设置这个属性:
jpa.hibernate.ddl-auto=validate
现在 Hibernate 不会生成任何东西。它只会检查 Java 表示是否与 DB 匹配。而且,我们不再需要混合一些Java和SQL来进行Hibernate自动生成,因此可以简洁且无需额外的责任:
@Entity
@Table(name = "users")
public class User {
@Id
@Column(name = "id")
@GeneratedValue
private UUID id;
@Column(name = "user_name", length = 64, nullable = false)
private String userName;
@Column(name = "email", length = 128, nullable = true)
private String email;
@Column(name = "receive_notifications", nullable = false)
private Boolean receiveNotifications;
}
如何正确使用迁移
- 每一次迁移都必须是幂等的,这意味着如果迁移多次应用,数据库状态保持不变。如果我们忽略这一点,我们可能会在回滚后出现错误,或者不应用导致失败的部分。
if not exists在大多数情况下,通过添加/之类的检查可以轻松实现幂等性,就像if exists我们上面所做的那样。 - 在编写一些 DDL 时,最好在一次迁移中尽可能多地添加,而不是创建多个。主要原因是可读性。如果在一个拉取请求中进行的相关更改位于一个文件中,那就更好了。
- 不要更改已经存在的迁移。这是一个明显但必需的。一旦迁移被编写、合并和部署,它必须保持不变。一些相关的更改必须单独完成。
- 每个开发人员都需要一个单独的环境。通常,它是本地的。原因是如果将某些迁移应用到共享环境,由于迁移工具的工作方式,它们之后会出现一些故障。
- 在测试数据库上运行所有迁移并检查一切是否正常的一些集成测试很方便。在合并之前检查 PR 正确性的构建中非常方便,并且可以避免许多基本错误。在此示例中,有一些集成测试可以开箱即用地进行检查。
- 最好使用
V{version+=1}__description.sql模式命名迁移而不是使用V{datetime}__description.sql. 第二种方便,有助于避免并行开发中的版本号冲突。但有时,发生名称冲突比在没有开发人员控制版本的情况下成功应用迁移要好。
结论
这是很多信息,但我希望你会发现它有帮助。如果您使用自动生成/更新模式 – 仔细查看模式发生了什么,因为它的行为可能出乎意料。添加尽可能多的描述来执行它总是一个好主意。
但是下次最好考虑迁移,因为它会减轻 Java 实体的负担,消除过多的责任,并通过对 DDL 的大量控制使您受益。
总结最佳实践:
- 写迁移是幂等的。
- 通过编写集成测试在测试数据库上一起测试所有迁移。
- 将相关更改包含在一个文件中。
- 每个开发人员都需要自己的数据库环境。
- 在编写迁移时仔细查看版本。
- 不要更改已经存在的。
您可以在GitHub 上找到完整的工作示例 。
learn-why-and-how-to-use-relational-database-migrations