你对机器学习感兴趣,也许你会涉足一点。
如果有一天你和朋友或同事谈论机器学习,你冒着有人问你的风险:
“那么,什么是机器学习?“
这篇文章的目的是为您提供一些需要考虑的定义和一个容易记住的方便的单行定义。
我们将从对该领域权威教科书的机器学习标准定义的感觉开始。最后,我们将制定一个开发人员对机器学习的定义和一个方便的单行代码,我们可以在任何时候被问到:什么是机器学习?
权威定义
让我们先来看看大学课程中常用的四本机器学习教科书。
这些是我们的权威定义,为我们对该主题进行更深入的思考奠定了基础。
我选择这四个定义是为了突出该领域的一些有用和不同的观点。通过经验,我们将了解到该领域确实是一团糟的方法,选择一个视角是取得进步的关键。
Mitchell的机器学习
Tom Mitchell 在他的《机器学习》一书中在序言的开头行提供了一个定义:
机器学习领域关注的问题是如何构建能够随着经验自动改进的计算机程序。
我喜欢这个简短而甜蜜的定义,它是我们在文章末尾提出的开发人员定义的基础。
请注意“计算机程序”的提及和“自动化改进”的提及。编写提高自己的程序,很刺激!
在他的介绍中,他提供了一个简短的形式,你会看到很多重复:如果计算机程序在任务 T 中的性能(由 P 衡量)随着经验 E 而提高,则可以说计算机程序从经验E中学习某类任务
T和性能度量P。
不要让术语的定义吓跑你,这是一种非常有用的形式主义。
我们可以使用这种形式作为模板,将E、T和P放在表中列的顶部,并以较少的歧义列出复杂的问题。它可以用作一种设计工具,帮助我们清楚地思考要收集哪些数据(E)、软件需要做出哪些决策(T)以及我们将如何评估其结果(P)。这种力量就是为什么它经常作为标准定义被重复。把它放在你的后口袋里。
统计学习的要素
统计学习的要素:数据挖掘、推理和预测是由三位斯坦福统计学家撰写的,自称是一个统计框架来组织他们的研究领域。
在序言中写道:
许多领域都在生成大量数据,而统计学家的工作是理解这一切:提取重要的模式和趋势,并理解“数据所说的内容”。我们称之为从数据中学习。
我理解统计学家的工作是使用统计工具在领域的背景下解释数据。作者似乎将机器学习的所有领域都纳入了这一追求。有趣的是,他们选择在书的副标题中加入“数据挖掘”。
统计学家从数据中学习,但软件也是如此,我们从软件学到的东西中学习。来自各种机器学习方法做出的决定和取得的结果。
模式识别
Bishop 在他的《模式识别与机器学习》一书的序言中评论道:
模式识别起源于工程学,而机器学习则起源于计算机科学。然而,这些活动可以被视为同一领域的两个方面……
阅读本文,您会觉得 Bishop 是从工程角度进入该领域的,后来学习并利用了计算机科学采用相同的方法。模式识别是一个工程或信号处理术语。
这是一种成熟的方法,我们应该效仿。更广泛地说,无论在哪个领域声称一种方法,如果它通过“从数据中学习”让我们更接近洞察或结果来满足我们的需求,那么我们可以决定将其称为机器学习。
算法视角
Marsland 在他的《机器学习:算法视角》一书中采用了 Mitchell 对机器学习的定义。
他在序言中提供了一个令人信服的注释,激励他写这本书:
机器学习最有趣的特征之一是它位于几个不同学科的边界,主要是计算机科学、统计学、数学和工程学。……机器学习通常作为人工智能的一部分进行研究,这将其牢牢地纳入计算机科学……理解这些算法为何起作用需要一定程度的统计和数学复杂性,而这往往是计算机科学本科生所缺少的。
这是富有洞察力和启发性的。
首先,他强调了该领域的多学科性质。我们从上面的定义中得到了一种感觉,但他为我们画了一条红色的大下划线。机器学习借鉴了各种信息科学。
其次,他强调了过于拘泥于既定观点的危险。具体来说,算法专家回避方法的数学内部运作的情况。
毫无疑问,统计学家回避实施和部署的实际问题的反例同样具有局限性。
文氏图Venn Diagram
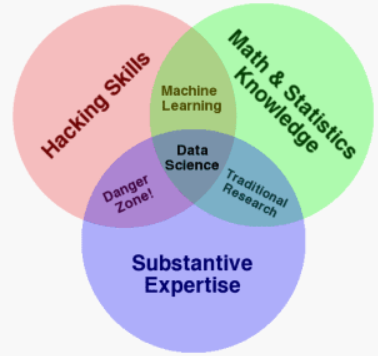
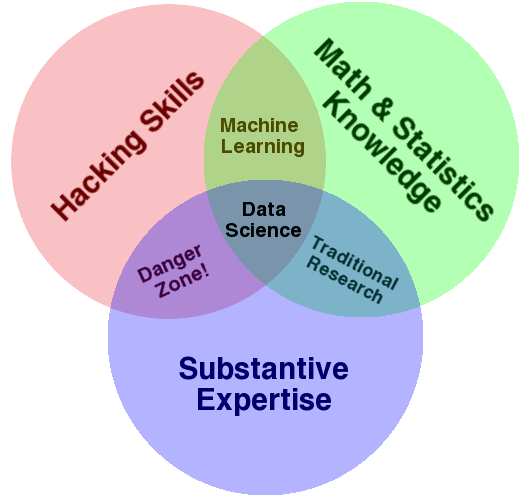
Drew Conway在 2010 年 9 月创建了一个很好的维恩图 ,这可能会有所帮助。
在他的解释中,他评论道:机器学习 = 黑客 + 数学和统计
{kind=link}
他还将 危险区域描述 为 黑客技能 + 专业知识。
在这里,他指的是那些知道足够危险的人。他们可以访问和构建数据,他们知道领域,他们可以运行方法并呈现结果,但不理解结果的含义。我认为这可能是 Marsland 暗示的。
开发人员对机器学习的定义
我们现在转向需要将所有这些分解为我们开发人员的具体细节。
我们首先看看那些抵制我们分解和程序解决方案的复杂问题。这体现了机器学习的力量。然后,我们制定出一个适合我们开发人员的定义,当我们被问到“那么,什么是机器学习?”由其他开发商。
复杂问题
作为开发人员,您最终会遇到顽固地抵制逻辑和程序解决方案的各类问题。
我的意思是,在某些问题类别中,坐下来写出解决问题所需的所有 if 语句是不可行或不划算的。
“亵渎!” 我听到你的开发者的大脑在呼喊。
这是真的。
以区分垃圾邮件和非垃圾邮件的决策问题为例。这是介绍机器学习时一直使用的示例。当电子邮件进入您的电子邮件帐户并决定将它们放入垃圾邮件文件夹或收件箱文件夹时,您将如何编写一个程序来过滤它们?
您可能会首先收集一些示例并查看它们并深入思考它们。您会在电子邮件中寻找垃圾邮件和非垃圾邮件的模式。您会考虑将这些模式抽象化,以便您的启发式方法在未来适用于新案例。您会忽略永远不会再看到的奇怪电子邮件。您会轻松获胜以提高准确性并为边缘情况制作特殊的东西。随着时间的推移,您会经常查看电子邮件,并考虑抽象出新模式以改进决策。
其中有一个机器学习算法,除了它是由程序员而不是计算机执行的。这种手动派生的硬编码系统只能与程序员从数据中提取规则并在程序中实现它们的能力一样好。
可以做到,但需要大量资源并且是维护的噩梦。
机器学习
在上面的示例中,我确信您的开发人员大脑,即您无情地寻求自动化的大脑部分,可以看到自动化和优化从示例中提取模式的元过程的机会。
机器学习方法就是这种自动化过程。
在我们的垃圾邮件/非垃圾邮件示例中,示例 ( E ) 是我们收集的电子邮件。任务 ( T ) 是一个决策问题(称为分类),将每封电子邮件标记为垃圾邮件与否,并将其放入正确的文件夹中。我们的绩效衡量标准 ( P ) 类似于准确度的百分比(正确决策除以做出的总决策乘以 100),介于 0%(最差)和 100%(最佳)之间。
准备这样的决策程序通常称为训练,其中收集的示例称为训练集,程序称为模型,如将垃圾邮件与非垃圾邮件分类问题的模型。作为开发人员,我们喜欢这个术语,模型有状态并且需要持久化,训练是一个执行一次并可能根据需要重新运行的过程,分类是执行的任务。这一切对我们来说都很有意义。
我们可以看到,上述定义中使用的一些术语并不适合程序员。从技术上讲,我们编写的所有程序都是自动化的,评论说机器学习自动学习没有意义。
Handy One-liner
所以,让我们看看我们是否可以使用这些部分并构建机器学习的开发人员定义。怎么样:
机器学习是根据数据对模型进行训练,该数据根据性能指标概括决策。
训练模型建议训练示例。模型表明通过经验获得的状态。概括决策表明基于输入和预测未来需要做出决策的看不见的输入做出决策的能力。最后,针对性能测量表明正在准备的模型有针对性的需求和定向质量。